![]()
Jun 20, 2024 DP-600 Exam Crack Test Engine Dumps Training With 82 Questions
Obtain the DP-600 PDF Dumps Get 100% Outcomes Exam Questions For You To Pass
NEW QUESTION # 23
You have a Fabric workspace that contains a DirectQuery semantic model. The model queries a data source that has 500 million rows.
You have a Microsoft Power Bl report named Report1 that uses the model. Report! contains visuals on multiple pages.
You need to reduce the query execution time for the visuals on all the pages.
What are two features that you can use? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
- A. OneLake integration
- B. automatic aggregation
- C. user-defined aggregations
- D. query caching
Answer: B,C
NEW QUESTION # 24
You need to provide Power Bl developers with access to the pipeline. The solution must meet the following requirements:
* Ensure that the developers can deploy items to the workspaces for Development and Test.
* Prevent the developers from deploying items to the workspace for Production.
* Follow the principle of least privilege.
Which three levels of access should you assign to the developers? Each correct answer presents part of the solution. NOTE: Each correct answer is worth one point.
- A. Viewer access to the Production workspace
- B. Viewer access to the Development and Test workspaces
- C. Admin access to the deployment pipeline
- D. Build permission to the production semantic models
- E. Contributor access to the Production workspace
- F. Contributor access to the Development and Test workspaces
Answer: A,C,F
Explanation:
To meet the requirements, developers should have Admin access to the deployment pipeline (B), Contributor access to the Development and Test workspaces (E), and Viewer access to the Production workspace (D). This setup ensures they can perform necessary actions in development and test environments without having the ability to affect production. References = The Power BI documentation on workspace access levels and deployment pipelines provides guidelines on assigning appropriate permissions.
NEW QUESTION # 25
You have a Fabric tenant that contains a warehouse. The warehouse uses row-level security (RLS). You create a Direct Lake semantic model that uses the Delta tables and RLS of the warehouse. When users interact with a report built from the model, which mode will be used by the DAX queries?
- A. Dual
- B. DirectQuery
- C. Import
- D. Direct Lake
Answer: D
NEW QUESTION # 26
You have a Fabric tenant that contains a lakehouse.
You are using a Fabric notebook to save a large DataFrame by using the following code.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 27
You have a Fabric tenant that contains a warehouse named Warehouse1. Warehouse1 contains three schemas named schemaA, schemaB. and schemaC You need to ensure that a user named User1 can truncate tables in schemaA only.
How should you complete the T-SQL statement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.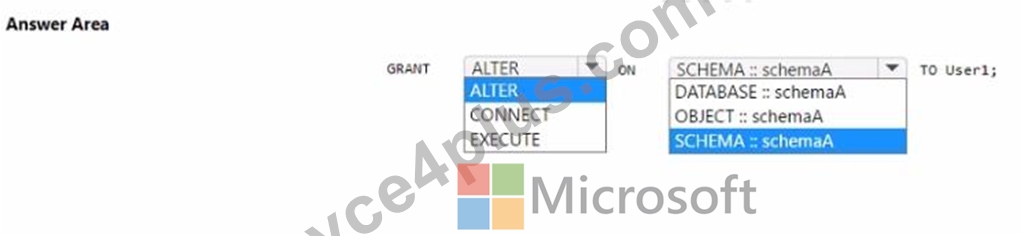
Answer:
Explanation: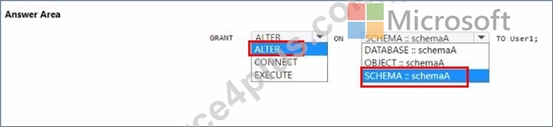
NEW QUESTION # 28
You have a Fabric workspace that uses the default Spark starter pool and runtime version 1,2.
You plan to read a CSV file named Sales.raw.csv in a lakehouse, select columns, and save the data as a Delta table to the managed area of the lakehouse. Sales_raw.csv contains 12 columns.
You have the following code.
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point.
Answer:
Explanation: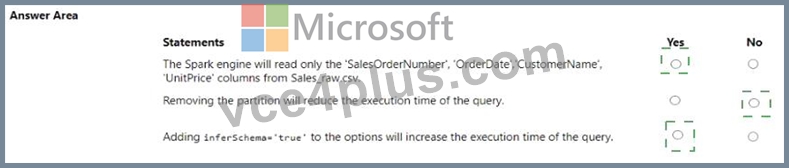
Explanation:
* The Spark engine will read only the 'SalesOrderNumber', 'OrderDate', 'CustomerName', 'UnitPrice' columns from Sales_raw.csv. - Yes
* Removing the partition will reduce the execution time of the query. - No
* Adding inferSchema='true' to the options will increase the execution time of the query. - Yes The code specifies the selection of certain columns, which means only those columns will be read into the DataFrame. Partitions in Spark are a way to optimize the execution of queries by organizing the data into parts that can be processed in parallel. Removing the partition could potentially increase the execution time because Spark would no longer be able to process the data in parallel efficiently. The inferSchema option allows Spark to automatically detect the column data types, which can increase the execution time of the initial read operation because it requires Spark to read through the data to infer the schema.
NEW QUESTION # 29
You need to create a data loading pattern for a Type 1 slowly changing dimension (SCD).
Which two actions should you include in the process? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
- A. Insert new rows when the natural key exists in the dimension table, and the non-key attribute values have changed.
- B. Insert new records when the natural key is a new value in the table.
- C. Update rows when the non-key attributes have changed.
- D. Update the effective end date of rows when the non-key attribute values have changed.
Answer: B,C
NEW QUESTION # 30
You are implementing two dimension tables named Customers and Products in a Fabric warehouse.
You need to use slowly changing dimension (SCO) to manage the versioning of data. The solution must meet the requirements shown in the following table.
Which type of SCD should you use for each table? To answer, drag the appropriate SCD types to the correct tables. Each SCD type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
For the Customers table, where the requirement is to create a new version of the row, you would use:
* Type 2 SCD: This type allows for the creation of a new record each time a change occurs, preserving the history of changes over time.
For the Products table, where the requirement is to overwrite the existing value in the latest row, you would use:
* Type 1 SCD: This type updates the record directly, without preserving historical data.
NEW QUESTION # 31
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression:
df .sumary ()
Does this meet the goal?
- A. No
- B. Yes
Answer: B
Explanation:
Yes, the df.summary() method does meet the goal. This method is used to compute specified statistics for numeric and string columns. By default, it provides statistics such as count, mean, stddev, min, and max.
References = The PySpark API documentation details the summary() function and the statistics it provides.
NEW QUESTION # 32
You have a Fabric tenant that contains a new semantic model in OneLake.
You use a Fabric notebook to read the data into a Spark DataFrame.
You need to evaluate the data to calculate the min, max, mean, and standard deviation values for all the string and numeric columns.
Solution: You use the following PySpark expression:
df .sumary ()
Does this meet the goal?
- A. No
- B. Yes
Answer: B
NEW QUESTION # 33
What should you recommend using to ingest the customer data into the data store in the AnatyticsPOC workspace?
- A. a stored procedure
- B. a dataflow
- C. a Spark notebook
- D. a pipeline that contains a KQL activity
Answer: B
Explanation:
For ingesting customer data into the data store in the AnalyticsPOC workspace, a dataflow (D) should be recommended. Dataflows are designed within the Power BI service to ingest, cleanse, transform, and load data into the Power BI environment. They allow for the low-code ingestion and transformation of data as needed by Litware's technical requirements. References = You can learn more about dataflows and their use in Power BI environments in Microsoft's Power BI documentation.
NEW QUESTION # 34
You have a Fabric tenant that contains a semantic model.
You need to prevent report creators from populating visuals by using implicit measures.
What are two tools that you can use to achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
- A. Tabular Editor
- B. Microsoft Power BI Desktop
- C. Microsoft SQL Server Management Studio (SSMS)
- D. DAX Studio
Answer: A,B
NEW QUESTION # 35
You have a Fabric tenant that contains a workspace named Workspace^ Workspacel is assigned to a Fabric capacity.
You need to recommend a solution to provide users with the ability to create and publish custom Direct Lake semantic models by using external tools. The solution must follow the principle of least privilege.
Which three actions in the Fabric Admin portal should you include in the recommendation? Each correct answer presents part of the solution.
NOTE: Each correct answer is worth one point.
- A. From the Tenant settings, enable Publish to Web
- B. From the Capacity settings, set XMLA Endpoint to Read Write
- C. From the Tenant settings, select Users can edit data models in the Power Bl service.
- D. From the Tenant settings, set Allow Azure Active Directory guest users to access Microsoft Fabric to Enabled
- E. From the Tenant settings, set Users can create Fabric items to Enabled
- F. From the Tenant settings, set Allow XMLA Endpoints and Analyze in Excel with on-premises datasets to Enabled
Answer: A,B,F
NEW QUESTION # 36
You have a Fabric workspace named Workspace1 and an Azure Data Lake Storage Gen2 account named storage"!. Workspace1 contains a lakehouse named Lakehouse1.
You need to create a shortcut to storage! in Lakehouse1.
Which connection and endpoint should you specify? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
When creating a shortcut to an Azure Data Lake Storage Gen2 account in a lakehouse, you should use the abfss (Azure Blob File System Secure) connection string and the dfs (Data Lake File System) endpoint. The abfss is used for secure access to Azure Data Lake Storage, and the dfs endpoint indicates that the Data Lake Storage Gen2 capabilities are to be used.
NEW QUESTION # 37
You have a Fabric tenant that contains a lakehouse named lakehouse1. Lakehouse1 contains a table named Table1.
You are creating a new data pipeline.
You plan to copy external data to Table1. The schema of the external data changes regularly.
You need the copy operation to meet the following requirements:
* Replace Table1 with the schema of the external data.
* Replace all the data in Table1 with the rows in the external data.
You add a Copy data activity to the pipeline. What should you do for the Copy data activity?
- A. From the Source tab, select Recursively
- B. From the Source tab, add additional columns.
- C. From the Destination tab, set Table action to Overwrite.
- D. From the Settings tab, select Enable staging
- E. From the Source tab, select Enable partition discovery
Answer: C
Explanation:
For the Copy data activity, from the Destination tab, setting Table action to Overwrite (B) will ensure that Table1 is replaced with the schema and rows of the external data, meeting the requirements of replacing both the schema and data of the destination table. References = Information about Copy data activity and table actions in Azure Data Factory, which can be applied to data pipelines in Fabric, is available in the Azure Data Factory documentation.
NEW QUESTION # 38
You have the source data model shown in the following exhibit.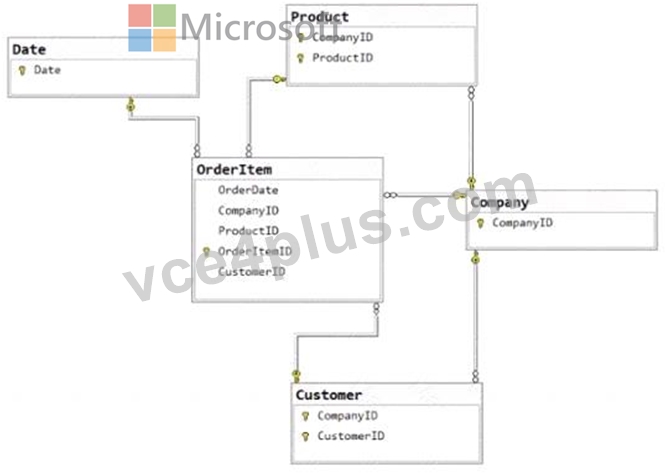
The primary keys of the tables are indicated by a key symbol beside the columns involved in each key.
You need to create a dimensional data model that will enable the analysis of order items by date, product, and customer.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
* The relationship between OrderItem and Product must be based on: Both the CompanyID and the ProductID columns
* The Company entity must be: Denormalized into the Customer and Product entities In a dimensional model, the relationships are typically based on foreign key constraints between the fact table (OrderItem) and dimension tables (Product, Customer, Date). Since CompanyID is present in both the OrderItem and Product tables, it acts as a foreign key in the relationship. Similarly, ProductID is a foreign key that relates these two tables. To enable analysis by date, product, and customer, the Company entity would need to be denormalized into the Customer and Product entities to ensure that the relevant company information is available within those dimensions for querying and reporting purposes.
References =
* Dimensional modeling
* Star schema design
NEW QUESTION # 39
......
DP-600 Exam Dumps Contains FREE Real Quesions from the Actual Exam: https://dumpsstar.vce4plus.com/Microsoft/DP-600-valid-vce-dumps.html